Projects

Data, Responsibly
Fairness, neutrality and transparency in data
If not used responsibly, big data technology can propel economic inequality, destabilize global markets and affirm systemic bias. While the potential opportunity of big data techniques is well accepted, the necessity of using these techniques responsibly should be discussed. In the society we envision, data and data analysis are fair, transparent and available equally to all.
Publications:
SIGMOD (demo) 2018, SSDBM 2017, SSDBM 2017
Portal
A query language for evolving graphs
Graphs are used to represent a plethora of phenomena, from the Web and social networks, to biological pathways, to semantic knowledge bases. Arguably the most interesting and important questions one can ask about graphs have to do with their evolution. Which Web pages are showing an increasing popularity trend? How does influence propagate in social networks? How does knowledge evolve? Much research and engineering effort today goes into developing sophisticated graph analytics and their efficient implementations, both stand-alone and in scope of data processing platforms. Yet, systematic support for scalable querying and analytics over evolving graphs still lacks. In this project we aim to build a system that fills this gap.
Publications:
EDBT 2017, SIGMOD 2017, WWW 2016
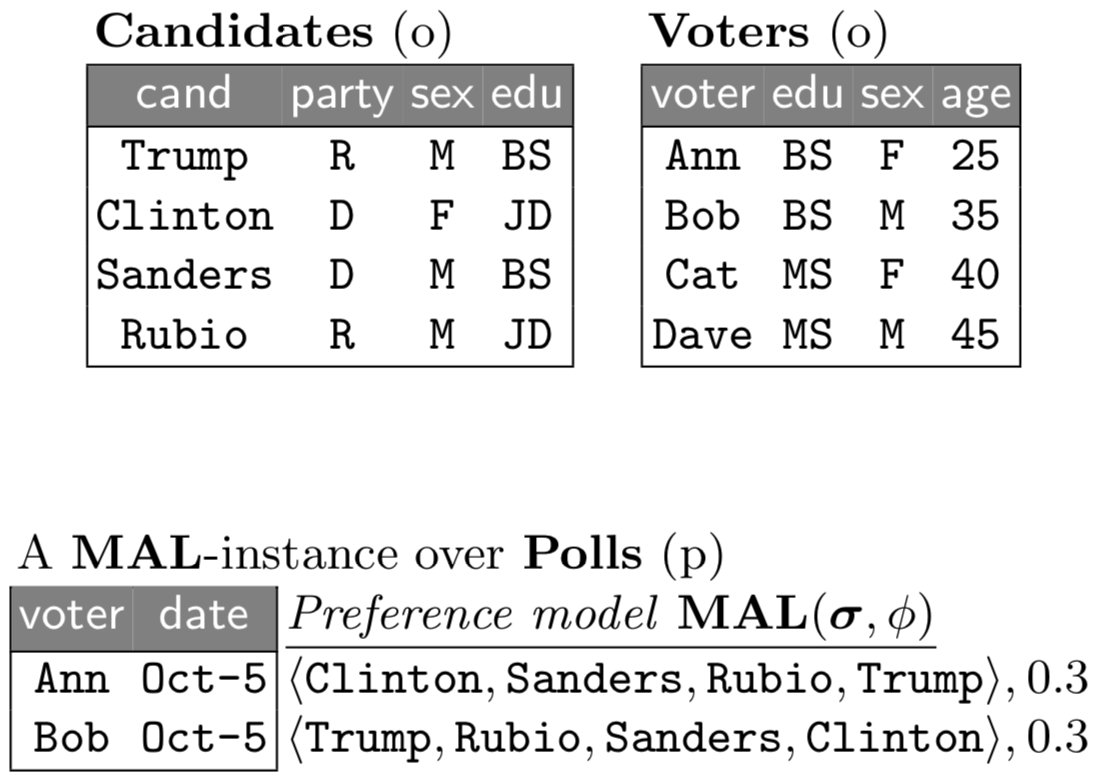
DB4Pref: Managing Preference Data
Streamline the management and analysis of preference data
Preferences are orders among a collection of items attributed to a population of judges. Preference data comes in a variety of forms, such as ranked lists and pairwise comparisons, and is ubiquitous in a plethora of applications across different domains. Over the past decade, there has been a sharp increase in the volume of preference data, in the diversity of applications that use it, and in the richness of preference data analysis methods. Examples of applications include rank aggregation in genomic data analysis, management of votes in elections and recommendation systems in e-commerce. In our work we look at two complementary aspects of preference management. In the first, we are enriching the relational database model with extensions that are specialized for handling preference data. In the second, we are developing novel analytics that are geared towards incomplete preferences.
Publications:
WebDB 2015, PVLDB 2014, CIDR 2013, EDBT 2011, CIKM 2009
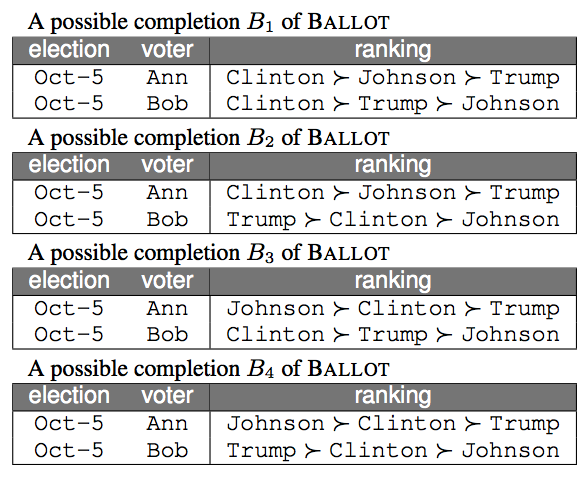
DBCOMSOC: Databases Meet Computational Social Choice
Databases Meet Computational Social Choice
Social choice underlies the equitable and efficient operation of a society. How does one aggregate preferences of individuals, arriving at a society-wide consensus? This question has been the subject of intense debate throughout history, dating as far back as ancient Greece, and, in the past two decades, has led to the development of computational social choice - an interdisciplinary area of research and practice that combines insights from mathematics, logic, economics, and computer science. One of the main foci of computational social choice are the algorithmic aspects of determining actual or potential winners in a poll or in an election. The main aim of this project is to develop a unifying framework that brings together preferences, rules, outcomes, contextual information, and database query languages.
Publications: